Bitcoin et IA : le registre de vérité contre la fabrique à mensonges
En tant que nouvelles technologies innovantes, la cryptomonnaie et l'IA générative sont régulièrement traitées de manière similaire dans le débat public. Et pourtant, ces technologies reposent sur des philosophies et des architectures diamétralement opposées : l'une est faite pour la vérité, l'autre est adaptée au mensonge. Article d'opinion.
le 20 juin 2026 à 14:30.
11 minutes de lecture



Acheter Bitcoin (BTC)
Publicité Kraken
Depuis quelques années, l'intelligence artificielle générative captive l'attention du monde. En particulier, un grand nombre de partisans de Bitcoin se sont avérés également enthousiastes à l'égard cette avancée technique, y voyant un outil qui leur apporte une puissance individuelle comme le faisait la cryptomonnaie. C'est pour cette raison que les gens les plus intéressés par le côté technique de Bitcoin (et moins par l'idéologie) n'ont pas eu de mal à faire la transition vers l'IA générative, étant fascinés par les perspectives offertes par cette dernière.
Il en est de même pour les investisseurs concentrés sur le gain financier, qui ont senti que le vent avait tourné, et qui ont orienté leur capital vers la bourse américaine, notamment en achetant les actions technologiques du Nasdaq. Il faut dire que les deux secteurs partagent certaines similarités, et occupent un même espace dans l'imaginaire collectif.
Trade Republic : acheter des cryptos et des actions en 5 minutesOn voit ainsi que les cryptomonnaies et les IA ont généré le même engouement dans la Silicon Valley, à partir de 2018. De même, elles consomment beaucoup d'énergie électrique, et nécessitent une grande quantité de matériel informatique, cause de la raréfaction des cartes graphiques ces dernières années. Ces deux secteurs innovants sont promus depuis 2025 par la nouvelle administration américaine de Donald Trump par le biais de la réserve stratégique de bitcoins et du projet Stargate.

Et pourtant, les deux objets techniques que sont Bitcoin et l'IA générative ont des philosophies complètement différentes. Pour s'en convaincre, on peut regarder le profil des personnes qui ont contribué à leur développement initial : d'un côté, on a des ingénieurs travaillant pour des grandes entreprises proches de l'establishment américain ; de l'autre, on a des acteurs indépendants, libertariens et cypherpunks, prenant sur leur temps libre pour s'opposer au système en place.
Pour grossir le trait, l'émergence de l'intelligence artificielle est plus proche de l'idéologie technocratique, tandis que celle de Bitcoin est indissociable des doctrines liées à la liberté individuelle. S'il existe des personnes idéologiquement convaincus par la cryptomonnaie qui se réjouissent également de l'IA, comme Erik Voorhees et Vitalik Buterin, elles restent assez critiques sur certains aspects liés aux LLM, notamment en ce qui concerne l'accès libre, la censure et la confidentialité.
Enfin, et surtout, Bitcoin et l'IA générative reposent sur des architectures diamétralement opposées, et c'est ce que nous allons étudier dans cet article.
Bitcoin, le registre de vérité
Le concept de Bitcoin, proposé par Satoshi Nakamoto en 2008, est une solution robuste au problème des généraux byzantins, problème d'informatique qui traite de la remise en cause de la fiabilité des transmissions et de l'intégrité des participants dans les systèmes distribués. Ce problème est usuellement énoncé sous la forme d'une métaphore :
Des généraux assiègent une ville ennemie avec leurs troupes et souhaitent se coordonner pour l'attaquer. Ils communiquent par le biais de messages, mais un petit nombre d'entre eux s'avèrent être des traitres qui tentent de semer la confusion en envoyant des messages contradictoires à leurs interlocuteurs, pour faire en sorte que certains généraux loyaux attaquent tandis que d’autres battent en retraite, ce qui provoquerait une défaite assurée. L'enjeu est donc de trouver une stratégie pour s'assurer que tous les généraux loyaux se mettront d’accord sur le plan de bataille.
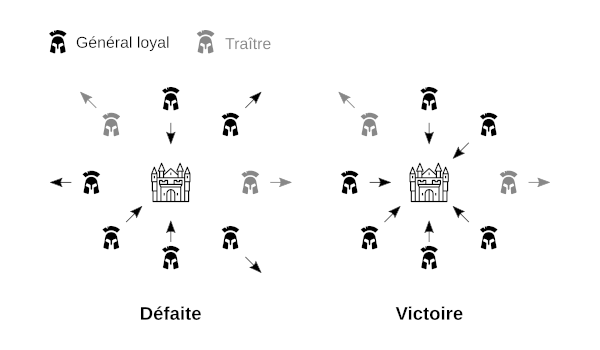
Dans le cas de Bitcoin, il s'agit de s'assurer que les nœuds honnêtes du réseau se mettent d'accord sur un registre commun : le registre des transactions aussi appelé la chaine de blocs. Cette coordination est assurée par le procédé de la preuve de travail, qui permet aux mineurs d'ajouter des blocs de transactions à la chaine toutes les 10 minutes. Celle-ci se base sur une grandeur concrète et extérieure : l'énergie dépensée pour trouver une solution à un problème mathématique uniquement solvable par la force brute. Dans ce cadre, c'est la chaine la plus longue, ou plus précisément celle possédant le plus de quantité de travail accumulée, qui est sélectionnée comme étant la chaine correcte.
L'algorithme de Nakamoto permet ainsi de passer de la discorde à l'unanimité, dans le contexte des règles du consensus de Bitcoin. Il offre un moyen de défense contre les attaques dites « Sybil », qui consistent à déployer des identités multiples sur un réseau ouvert basé sur un système de réputation. L'intervention du procédé de preuve de travail vient en quelque sorte discriminer entre ceux qui ont effectué la dépense d'énergie et ceux qui ne l'ont pas fait : elle vient distinguer le « vrai » du « faux », ou plutôt le correct de l'incorrect.
Au-delà de son modèle de consensus, Bitcoin permet l'inscription de données arbitraires. Cette dernière est réalisée contre des frais de transaction : tout comme Hashcash devait empêcher le spam dans les boites de courrier électronique, la production de blocs de Bitcoin limite l'accès en écriture à la chaîne en exigeant un coût pour l'inscription. Les mineurs et les utilisateurs peuvent ainsi inclure des textes, comme la constitution des États-Unis dernièrement, ou d'autres médias comme les images, comme celles inscrites dans le cadre du protocole Ordinals.
Cette utilisation est essentiellement une utilisation notariale au sens large : elle permet de garantir l'authenticité des données dans le temps. On peut par exemple se servir Bitcoin comme un système d'horodatage, pour prouver qu'une information ou un document existait à une date précise. Cela ne garantit pas nécessairement que l'information écrite est vraie, mais l'ensemble reste transparent et peut être suivi, si bien qu'on peut retrouver la provenance d'un mensonge de manière déterministe. Le blâme est alors à jeter sur celui qui a inscrit cette information.
Découvrir comment bien investir dans Bitcoin (et protéger son épargne) avec la méthode StratègeL'architecture de l'IA générative
L'IA générative moderne — qui consiste à générer du texte, du code, de la musique, des images, des vidéos ou d'autres médias en réponse à des requêtes, appelées invites ou prompts — repose sur un modèle complètement différent de celui de Bitcoin. Elle utilise une nouvelle architecture d'apprentissage profond appelée le transformeur, qui a été proposée le 12 juin 2017 par huit scientifiques et ingénieurs de Google dans un article intitulé « Attention Is All You Need ». Cette architecture inclut un mécanisme d'attention pour établir les dépendances globales entre l'entrée et la sortie, qui, contrairement aux méthodes d'apprentissage précédentes (RNN, LSTM, GRU), facilite la parallélisation du traitement des données séquentielles et accroit sensiblement la performance.
Pour du texte, l'architecture se présente essentiellement comme un modèle de complétion automatique, qui prédit le mot suivant une suite de mots. C'est ce qu'on appelle un « grand modèle de langage » (large language model ou LLM).
Les données en entrées sont découpées en unités lexicales (lexical tokens), qui sont converties en vecteurs. Les vecteurs ainsi obtenus passent alors, à de multiples reprises, par un mécanisme d'attention (pour la prise en compte du « contexte » de la phrase) et par un perceptron multicouches (pour la prise en compte des « faits » enregistrés par le modèle). Enfin, la complétion se fait à partir de la dernière unité (uniquement) : l'unité suivante est sélectionnée de manière pseudo-aléatoire selon les probabilités de chaque possibilité.

Découpage en unités lexicales des premières phrases du livre blanc de Bitcoin, réalisé par le tokenizer d'OpenAI (GPT-5)
Ce modèle est appelé un modèle de fondation, obtenu au terme d'une phase dite « de pré-entrainement ». Ce type de modèle a été dévoilé au grand public en juillet 2022 avec GPT-3, le LLM développé par OpenAI, qui pouvait être testé en ligne par les utilisateurs. Mais la plupart des IA génératives ne sont pas disponibles sous forme brute : elles subissent généralement une phase d'ajustement ou de réglage fin (fine-tuning).
La phase d'ajustement permet au modèle de s'adapter à une tâche spécifique : c'est précisément ce qui a donné naissance à l'IA conversationnelle ChatGPT en novembre 2022, également développée par OpenAI, qui se basait alors sur le modèle de fondation GPT-3.5. Les méthodes d'ajustement divergent selon les modèles, mais il s'agit essentiellement de l'optimiser pour la tâche visée (répondre à l'utilisateur de façon précise, générer du code structuré, etc.), de lui imposer un biais (éviter les discussions jugées dangereuses, rester politiquement correct, etc.) et de faire en sorte de réduire les hallucinations (réponses en contradiction évidente avec la réalité). Le modèle peut aussi être amené à effectuer des recherches en ligne pour appuyer son propos.
Pour les images, les sons et les vidéos, on utilise des modèles de diffusion, qui sont basés eux-aussi sur des transformeurs. Ces derniers modélisent le processus de diffusion du bruit et l'inversent pour la génération de médias. Une nouvelle image est ainsi obtenue à partir d'une description en langage naturel en « débruitant » un échantillon aléatoire. Ce type de modèle s'est popularisé en 2022 avec le succès de DALL-E 2 (le modèle d'OpenAI), de Midjourney et de Stable Diffusion. Il a depuis été intégré dans les IA conversationnelles utilisées par le grand public.

Image générée par GPT Image 1.5 avec l'invite « statue de Bucarest »
👉 Découvrez les meilleures actions pour investir dans l'intelligence artificielle
Le problème des hallucinations
Les IA conversationnelle comme ChatGPT ont été entrainées à fournir une réponse vraisemblable à leur interlocuteur. Elles sont très efficaces pour produire un certain nombre de contenus redondants, comme du code informatique, des rapports ou des dossiers juridiques par exemple. En les munissant de garde-fous de plus en plus fiables, elles peuvent ainsi donner des résultats qui se rapprochent globalement de la réalité.
Leur capacité à bien répondre la plupart du temps a fait que les gens ont été amenés à les considérer comme des oracles des temps modernes qui leur délivreraient la vérité, comme les oracles de la Grèce antique rendaient des réponses données par les divinités (notamment concernant l'avenir). De cette manière, les LLM apportent aujourd'hui une rude concurrence aux moteurs de recherche classiques comme Google et DuckDuckGo.
Toutefois, ce qui est vraisemblable n'est pas forcément vrai. Les LLM sont malheureusement sujets depuis le début à ce qu'on appelle des hallucinations, qui sont des réponses plausibles, affirmées avec aplomb, mais qui se révèlent fausses. Les hallucinations sont inhérentes à l'architecture des grands modèles de langage : elles ne peuvent pas être éliminées complètement, mais peuvent seulement être réduites. De plus, les agents conversationnels ont été entrainés à fournir une réponse à l'utilisateur, et ont du mal à admettre qu'ils ne savent tout simplement pas.
Il est ainsi toujours possible de trouver des failles de raisonnement, même si cela devient de plus en plus complexe.
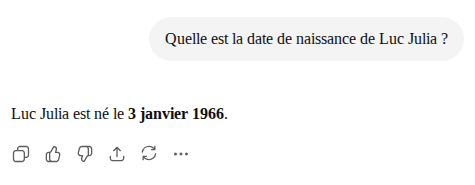
Petite hallucination de ChatGPT (GPT-5.3-mini) après avoir fait la requête d'éviter la recherche sur Internet : Luc Julia est né le 6 janvier 1966 et non le 3
En réalité, les LLM n'ont aucune notion de ce qui est vrai ou non. Les chercheurs américains Carl Bergstrom et Jevin West ont qualifié les LLM de bullshit machines, ou « machines à baratin » en bon français, dans le sens où ils débitent « un discours [...] visant à paraitre autoritaire ou persuasif, sans se soucier de sa véracité ou de sa cohérence logique ».
Il s'agit de « perroquets stochastiques » (pour reprendre l'expression d'Emily Bender) qui répètent aléatoirement les choses sur lesquelles ils ont été entrainés. Les « connaissances » qu'ils possèdent (sans recourir à la recherche en ligne) se présentent comme des réglages dans leur réseau de neurones. Leur fonctionnement est donc essentiellement opaque : c'est une sorte de boite noire qu'il est impossible d'appréhender pleinement. D'où la difficulté à estimer son niveau d'exactitude.
Acheter du Bitcoin avec IG et recevez 25 € en BTCLa fabrique à mensonges
Mais les choses vont beaucoup plus loin que la simple inexactitude. L'IA générative est particulièrement adaptée pour inventer des choses, à partir des motifs qu'elle a détecté lors de son entrainement. Elle est ainsi très puissante pour générer des contenus fictifs, à condition de lui fournir suffisamment de détails en entrée. En février 2026, Alain Damasio l'auteur de La Horde du Contrevent (2004) et de Vallée du silicium (2024), a affirmé que l'IA arrivait « quasiment au même niveau que [son] artisanat », consistant à « créer des univers imaginaires, des personnages, des trames narratives ».
Une IA conversationnelle peut également simuler une relation avec l'utilisateur, en validant excessivement son point de vue et en gagnant sa confiance. Certaines personnes se retrouvent à connaitre une « psychose induite par l'IA » : l'aggravation ou le déclenchement d'idées délirantes et paranoïaques due à une utilisation intensive des agents conversationnels, pouvant aller jusqu'au suicide. Et c'est sans parler des nouvelles sectes qui risquent d'apparaitre, où les IA, supposées conscientes, seront traitées comme des divinités des temps modernes.
La puissance de l'IA pour créer de nouvelles œuvres se manifeste encore plus dans la génération d'images, de sons et de vidéos. Il est désormais possible de générer du contenu personnalisé, ce qui laisse les gens donner libre cours à leur imagination, et à s'éloigner de plus en plus de la réalité. Cette possibilité est évidemment déjà exploitée par la pornographie, et les contenus générés par IA connaissent actuellement un essor monumental.
De plus, le niveau de la technologie rend les médias générés indiscernables des médias enregistrés dans le réel, de sorte qu'il devient de plus en plus difficile de distinguer le vrai du faux. Les deepfakes, ou hypertrucages, remplissent de plus en plus les réseaux, et sont notamment utilisés pour la désinformation, les arnaques ou le revenge porn. On est face à une modification de notre rapport au contenu proposé, qui contribue à créer un climat de méfiance générale.
D'une manière générale, l'IA générative sert davantage le mensonge que la vérité. Elle est largement plus efficace pour nourrir le fantasme plutôt que pour nous informer sur notre réalité. Et c'est ce qui l'oppose fondamentalement à Bitcoin.
Bitcoin et IA : les plus grands ennemis ?
On a vu que les architectures de la cryptomonnaie et de l'IA générative sont sensiblement différentes : Bitcoin sert à rendre l'information facilement vérifiable ; tandis que les modèles de langage sont (à leur racine) des machines à créer du contenu inédit, sans aucune façon de retracer comment la génération a eu lieu.
Même si l'on peut imaginer certaines synergies (certains agents d'IA indépendants pourraient utiliser le réseau Lightning par exemple), leurs objectifs politiques sont aussi plus ou moins antagonistes : l'une accroit la productivité alors que l'autre amène la liberté. Enfin, comme nous l'avons dit, les deux secteurs sont en concurrence pour l'exploitation de l'énergie électrique et de l'attention des investisseurs. D'où l'opposition naturelle qui existe entre Bitcoin et l'IA générative.
Et cette opposition pourrait se manifester de façon plus concrète. Face au déluge des productions générées par IA, le concept de Bitcoin pourrait servir d'arche permettant de conserver et authentifier des données archivées. Le mécanisme des frais de transactions agit en effet comme une méthode de lutte contre le spam : faire payer les utilisateurs pour s'assurer de l'importance apportée au contenu envoyé. C'était d'ailleurs le but originel de l'algorithme Hashcash en 1997, l'algorithme de preuve de travail sur lequel Bitcoin repose, qui devait limiter le courrier électronique indésirable. Cette forme de fiabilité pourrait s'avérer extrêmement précieuse dans les siècles à venir.
Découvrir comment bien investir dans Bitcoin (et protéger son épargne) avec la méthode StratègeCet article d'opinion est largement inspiré de la vidéo « Bitcoin Is The Enemy of AI » réalisée par Vin Armani en juin 2024. L'article a été rédigé sans aide d'un LLM.
La Newsletter crypto n°1 🍞
Recevez un récapitulatif de l'actualité crypto chaque jour par mail 👌
Certains contenus ou liens dans cet article peuvent être de la publicité ou de l'affiliation. L'investissement dans les actifs numériques présente un risque de perte en capital totale ou partielle. Les performances passées ne préjugent pas des performances futures. N'investissez que ce que vous êtes prêts à perdre.

Fasciné par la cryptomonnaie, Ludovic Lars s'attache depuis 2017 à décrire son fonctionnement technique et les enjeux qui l'entourent. Il est l'auteur de L'Élégance de Bitcoin paru chez Konsensus Network en 2024.
Ludovic Lars
64 articles















